
Computer Applications in Pharmacy Hub
Bioinformatics – Concepts, Databases, and Impact on Vaccine Discovery UNIT 4
By Arvind Sharma, B.Pharm, M.Pharm, Assistant Professor, MUIT
UNIT 4: BIOINFORMATICS
COMPREHENSIVE CLASS NOTES: BIOINFORMATICS
Table of Contents
1. INTRODUCTION TO BIOINFORMATICS
1.1 Definition
- Bioinformatics: An interdisciplinary science field.
- Combines biology, computer science, information engineering, mathematics, and statistics.
- Purpose: To analyze and interpret biological data.
- Develops methods and software tools for understanding complex biological information.
Key Distinction:
- Bioinformatics: Uses computation to better understand biology.
- Biological Computation: Uses bioengineering and biology to build biological computers.
- Computational Biology: Often considered synonymous with bioinformatics.
1.2 Concept of Bioinformatics
- Bioinformatics (or life science informatics) has emerged as a new branch of biotechnology.
- Offers fundamental tools to biologists to accelerate commercialization of biotechnology.
- Represents the convergence of biotechnology and information technology.
| Core Functions | Description |
|---|---|
| Data mining | In life sciences |
| Analysis and data searching | For biological information |
| Data integration and simulation | Combining and modeling data |
| Molecular biological data processing | Handling molecular level data |
| Genome sequence analysis | Studying genetic sequences |
| Data storage and management | Organizing and maintaining data |
- Recent Focus: Genomics occupies a central role in bioinformatics, particularly in understanding basic life processes.
2. OBJECTIVES OF BIOINFORMATICS
| Objective Category | Objective |
|---|---|
| Primary Objectives | Organize vast amounts of molecular biology data efficiently. |
| Develop tools that aid in the analysis of such data. | |
| Interpret the results accurately and meaningfully. | |
| Applied Objectives | Study normal biological processes. |
| Analyze various approaches to improve biological processes. | |
| Aid in improving drug discovery techniques. | |
| Help in developing new target drugs for fatal diseases. | |
| Enable study and research on development of preventive medicines for life-threatening diseases like cancer. |
3. NEED FOR BIOINFORMATICS
- The need for bioinformatics has arisen from several critical factors.
3.1 Data Explosion
- Recent explosion of publicly available genomic information.
- Results from major projects like the Human Genome Project.
- Massive amounts of DNA and protein sequence data.
3.2 Scientific Understanding
- Gain better understanding of gene analysis.
- Improve taxonomy classification.
- Study evolution and phylogenetic relationships.
3.3 Pharmaceutical Applications
- Work efficiently on rational drug design.
- Reduce drug development duration/time.
- Lower costs in pharmaceutical research.
3.4 Technological Advancement
- Unprecedented growth of information technology.
- Extraordinary growth in molecular biology.
- Advances in recombinant DNA technologies.
- Integration of these interrelated studies into cutting-edge technology.
4. APPLICATIONS OF BIOINFORMATICS
| Application Area | Benefit/Purpose |
|---|---|
| Analyze Biological Processes | Understanding cellular and molecular mechanisms. |
| Drug Discovery | Aids in improving and accelerating drug discovery. |
| Target Drug Development | Helps in developing new target drugs. |
| Research & Development | Supports scientific study and research. |
| Personalized Medicine | Enables tailored treatment approaches. |
| Disease Diagnosis | Assists in identifying genetic disorders. |
| Evolutionary Studies | Traces evolutionary relationships. |
| Protein Structure Prediction | Models 3D protein structures. |
5. BIOINFORMATICS DATABASES
5.1 Introduction to Databases
- Databases are essential for bioinformatics research and applications.
- They serve as organized repositories of biological information.
| Characteristic | Description |
|---|---|
| Data Content | Contain empirical data (from experiments) and predicted data (from computation). Most commonly contain both. |
| Specificity | May be specific to a particular organism, pathway, or molecule. |
| Integration | Can incorporate data compiled from multiple other databases. |
| Variety | Vary in format, access mechanism, and public/private status. |
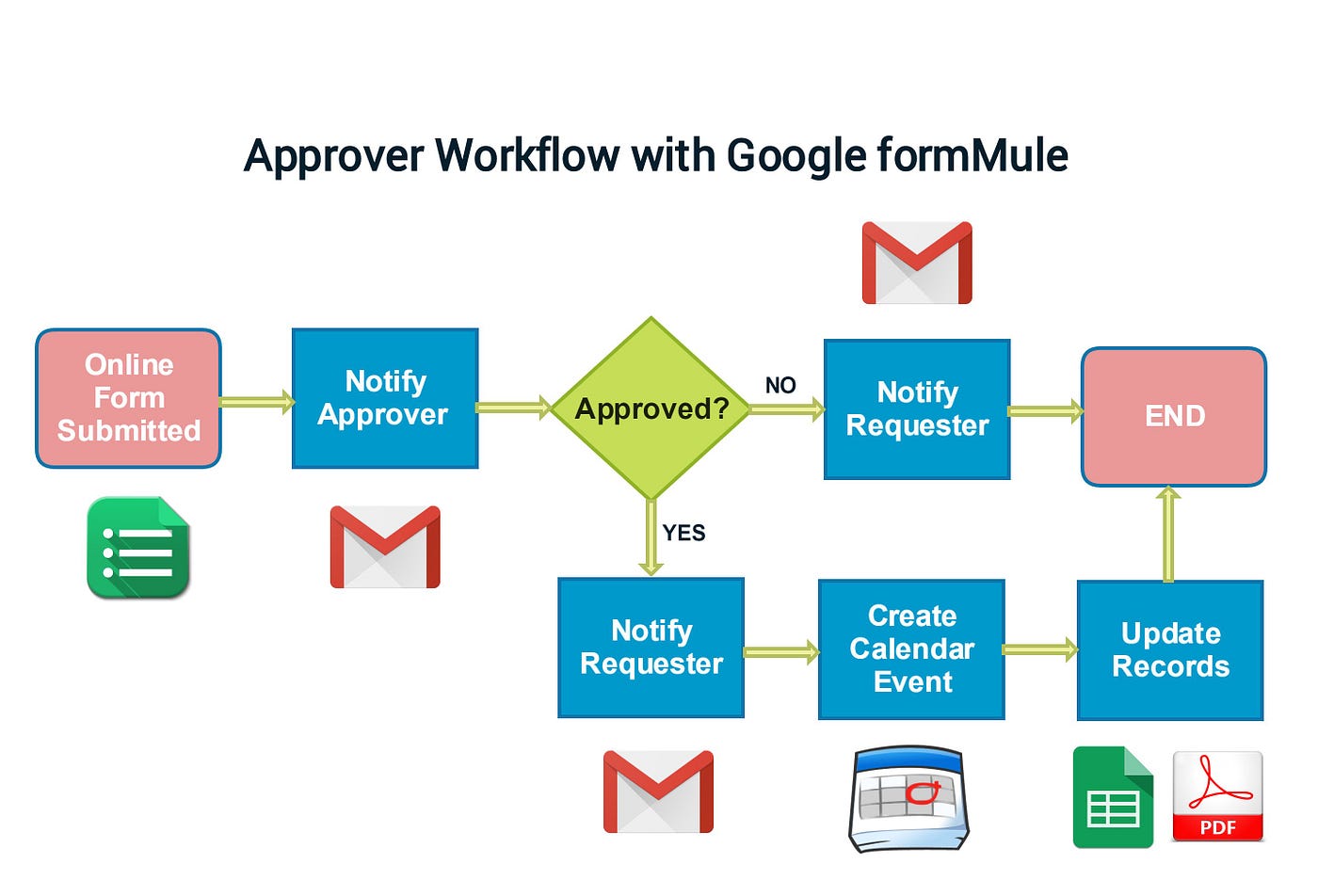
5.2 Types of Biological Databases
| Database Type | Information Stored | Examples |
|---|---|---|
| Bibliographic Database | Literature and research papers | PubMed, MEDLINE |
| Taxonomic Database | Classification and species data | NCBI Taxonomy, ITIS |
| Nucleic Acid Database | DNA sequences and information | GenBank, EMBL, DDBJ |
| Genomic Database | Gene information and genomes | Ensembl, UCSC Genome Browser |
| Protein Database | Protein sequences and data | UniProt, Swiss-Prot, PIR |
| Enzyme/Metabolic Pathway | Metabolic pathways and enzymes | KEGG, BioCyc, BRENDA |
| Structure Database | 3D molecular structures | PDB (Protein Data Bank) |
| Disease Database | Disease-related information | OMIM, Disease Ontology |
| Chemical Database | Small molecules and compounds | PubChem, ChEMBL |
| Microarray Database | Gene expression data | GEO, ArrayExpress |
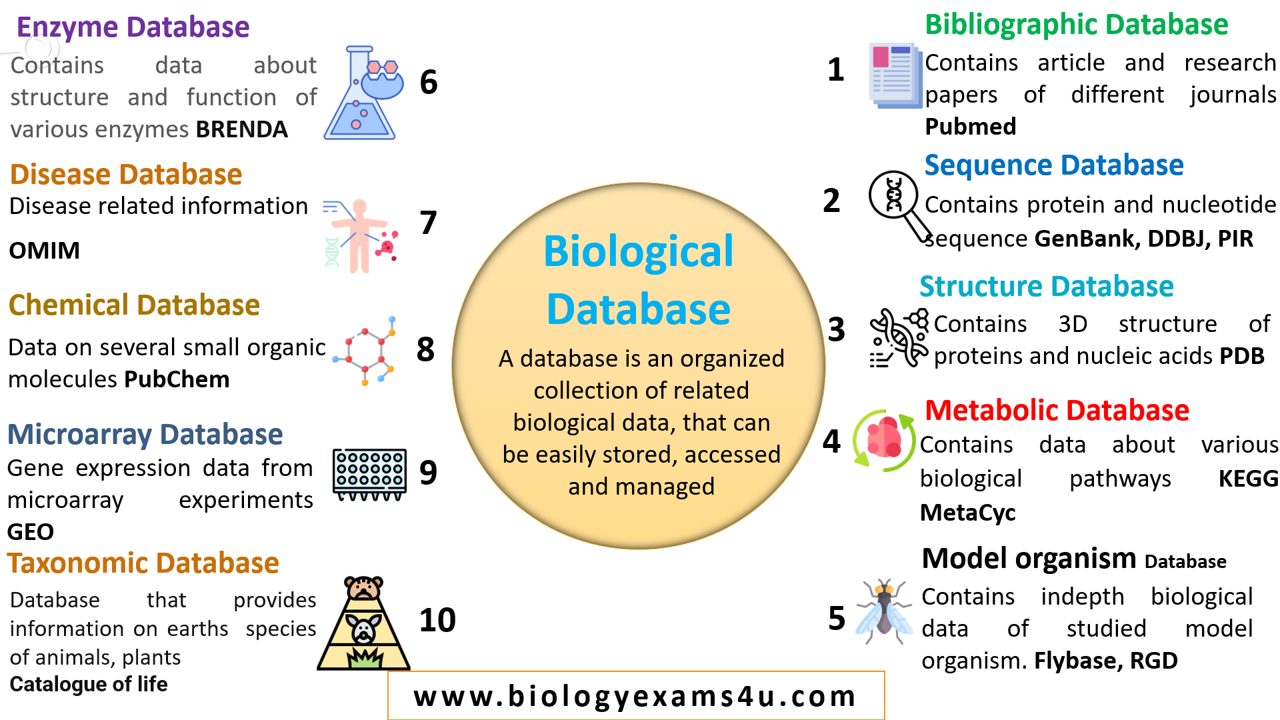
5.3 Commonly Used Bioinformatics Databases
| Application | Databases |
|---|---|
| Biological Sequence Analysis | GenBank, UniProt |
| Structure Analysis | Protein Data Bank (PDB) |
| Protein Families & Motif Finding | InterPro, Pfam |
| Next Generation Sequencing | Sequence Read Archive (SRA) |
| Network Analysis | KEGG, BioCyc, STRING, BioGRID |
| Metabolic Pathway Analysis | KEGG, BioCyc, MetaCyc |
| Interaction Analysis | STRING, BioGRID, IntAct |
| Functional Networks | GeneMANIA, STRING |
| Synthetic Genetic Circuits | GenoCAD |
| Drug-DNA Interaction | PREDDICTA |
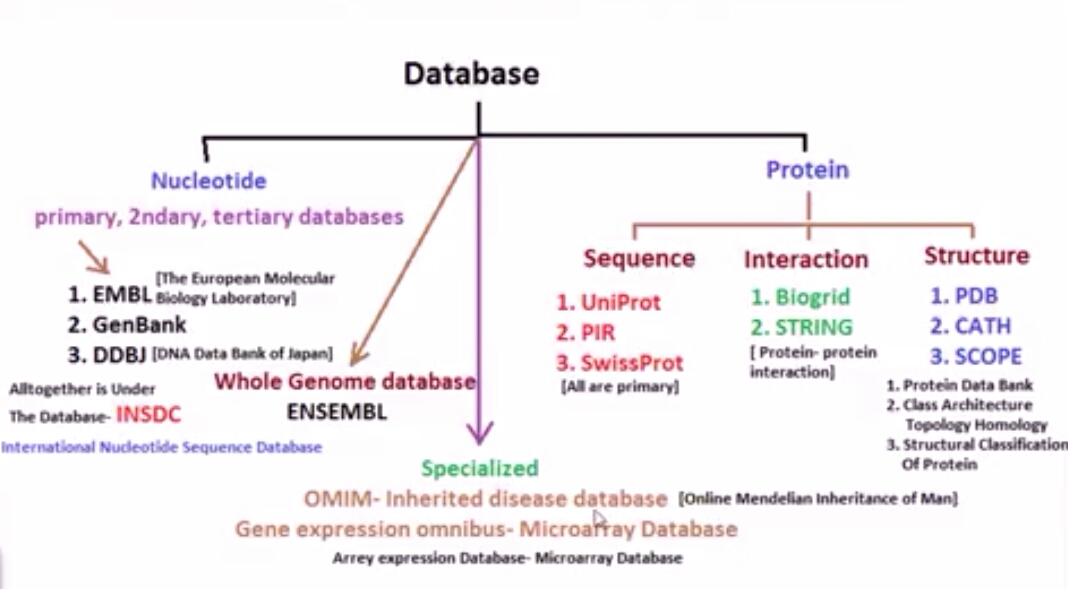
5.4 Classification of Bioinformatics Databases
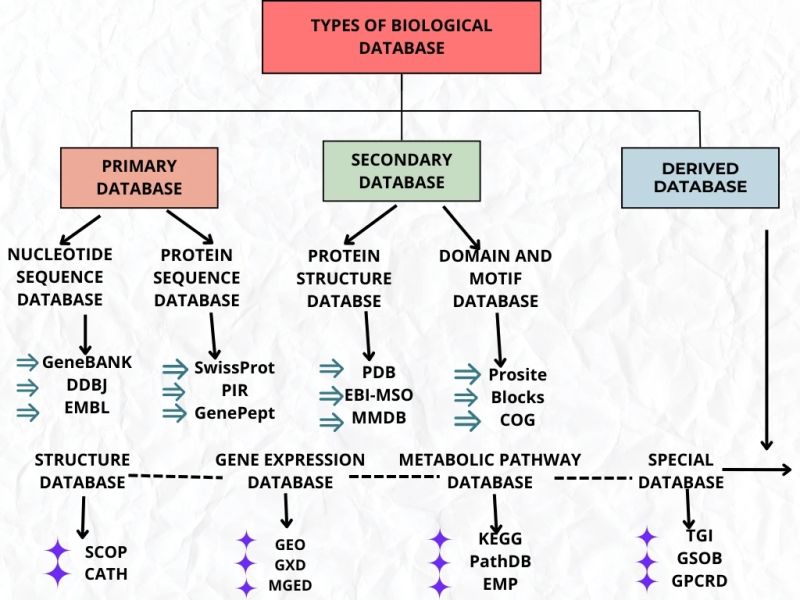
- Databases can be classified on the basis of:
| Category | Database Types | Examples |
|---|---|---|
| a) Data Type | Sequence Databases Structure Databases Literature Databases Pathway Databases Expression Databases | DNA, RNA, protein sequences 3D molecular structures Scientific publications Metabolic and signaling pathways Gene expression data |
| b) Data Source | Primary Databases Secondary Databases Composite Databases | Original experimental data (GenBank, PDB, UniProt) Analyzed/derived data (Pfam, PROSITE, InterPro) Combine data from multiple sources (NR, UniRef) |
| c) Database Design | Relational Databases Object-Oriented Databases NoSQL Databases | Use structured query language (SQL) Store complex data objects Handle unstructured big data |
| d) Special Category | Organism-Specific Disease-Specific Technology-Specific | FlyBase (Drosophila), WormBase (C. elegans) Cancer Genome Atlas, OMIM GEO (microarray), SRA (sequencing) |
6. IMPACT OF BIOINFORMATICS IN VACCINE DISCOVERY
6.1 Overview
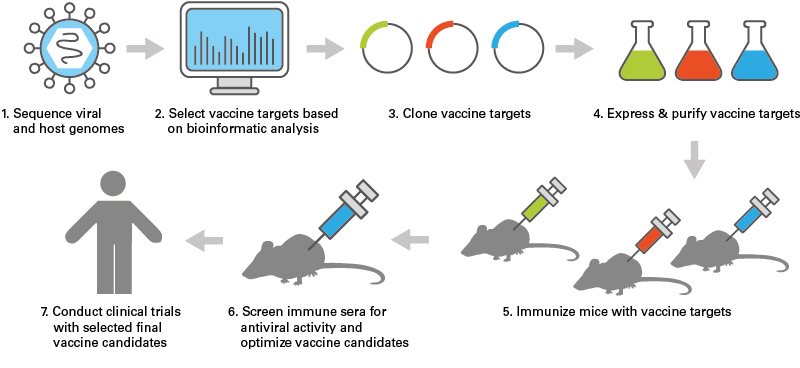
- Bioinformatics has revolutionized vaccine discovery.
- Enables faster, more effective, and cost-efficient development processes.
- Combines biology with pharmacology.
- Reduces time and cost required to develop high-quality vaccines with fewer side effects.
6.2 Role of Genomics in Vaccine Development
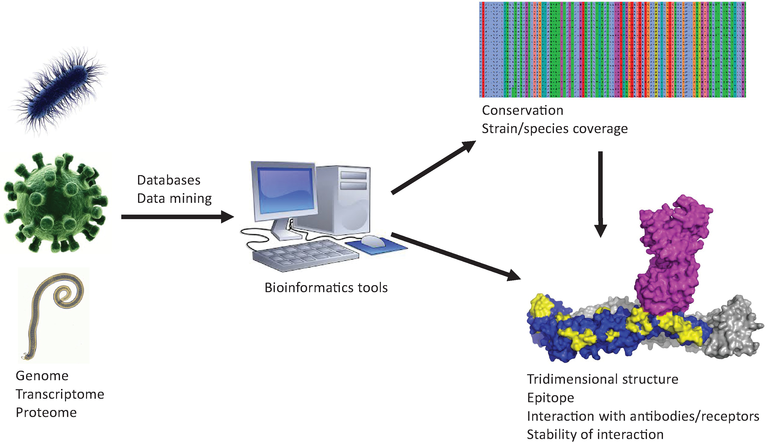
- The science of genomics plays a vital role in improving human health globally.
Key Principle: If the genome sequence of a pathogen is available, a vaccine can be designed to target that sequence, preventing disease occurrence.
Genome Sequencing
Obtain complete genetic sequence of pathogen
Obtain complete genetic sequence of pathogen
↓
Gene Identification
Use software programs to identify individual genes
Use software programs to identify individual genes
↓
Outcome Prediction
Analyze gene functions and interactions
Analyze gene functions and interactions
↓
Target Selection
Identify potential vaccine targets
Identify potential vaccine targets
6.3 Vaccine Design Strategy
- Designing an ideal vaccine depends on:
- Targeted Pathogens: Understanding pathogen biology.
- Drug Interactions: Studying interactions with existing drugs.
- Host-Pathogen Interactions: Analyzing how pathogens interact with host.
| Advantages of Bioinformatics Approach | Benefit |
|---|---|
| Rapid genome sequencing | Of various pathogens. |
| Large-scale data collection | About hosts and pathogens. |
| Identification of conserved regions | Across strains. |
| Prediction of antigenic epitopes | For vaccine design. |
| Reduced development time | From years to months. |
6.4 Computational Vaccine Design Workflow
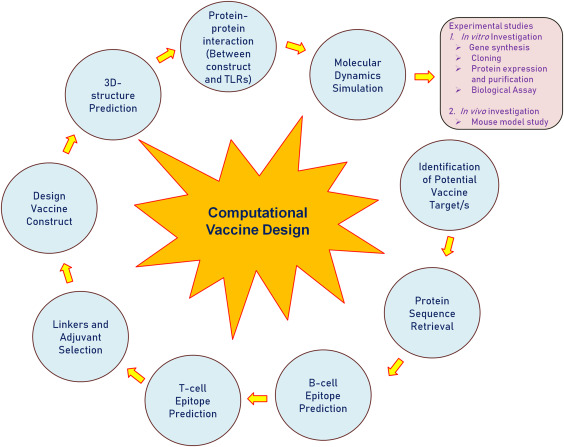
Stage 1: Target Selection
- Retrieve amino acid sequences from databases.
- Identify structural and non-structural proteins.
- Select potential vaccine targets.
↓
Stage 2: Epitope Prediction
- Predict MHC Class I epitopes (CTL).
- Predict MHC Class II epitopes (HTL).
- Predict B-cell epitopes.
- Evaluate antigenicity, allergenicity, immunogenicity.
- Assess toxicity and population coverage.
↓
Stage 3: Vaccine Construction
- Design vaccine construct with linkers and adjuvants.
- Predict tertiary structure.
- Analyze physicochemical parameters.
↓
Stage 4: Molecular Analysis
- Perform molecular docking.
- Refine intermolecular bonds.
- Conduct molecular dynamics simulation.
↓
Stage 5: In Silico Validation
- Immune response simulation.
- Codon optimization and cloning.
- Final validation before laboratory testing.
6.5 Epitope-Based Vaccine Design
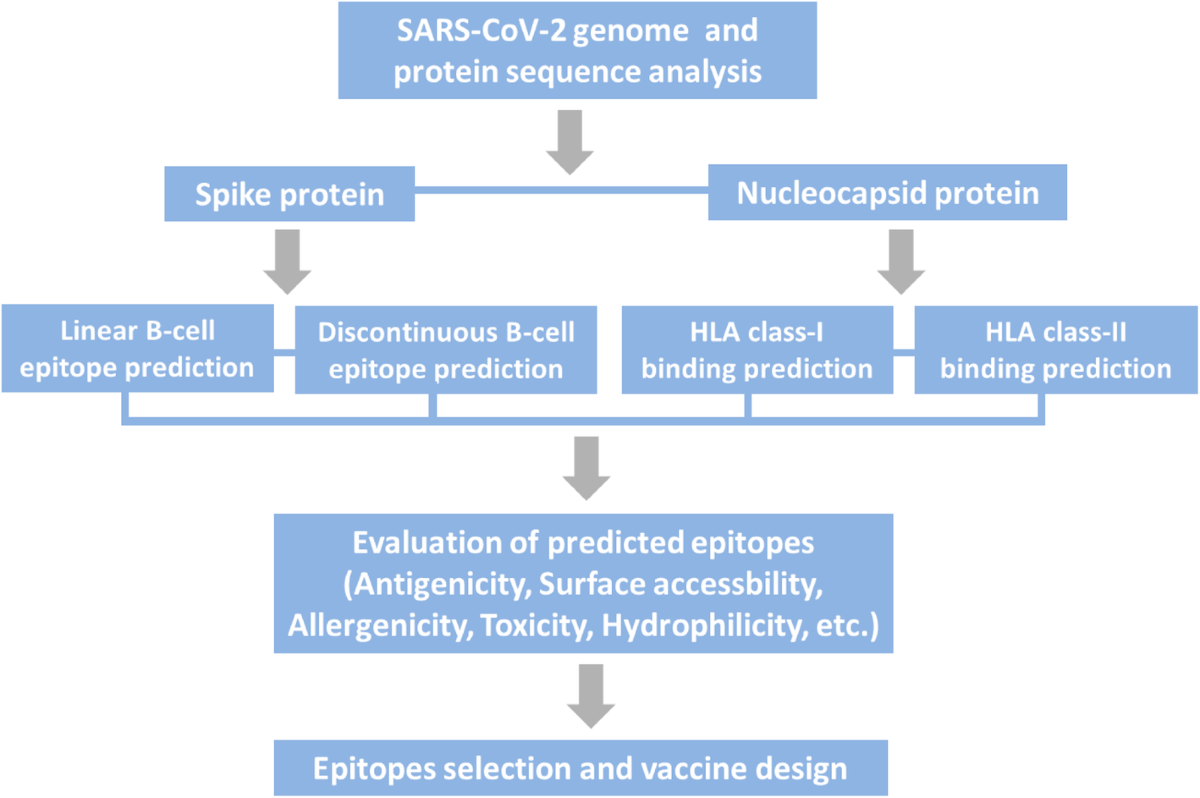
Example: SARS-CoV-2 Vaccine Development
- Genome and Protein Sequence Analysis:
- Analyze spike protein and nucleocapsid protein.
- Epitope Prediction:
- Linear B-cell epitope prediction.
- Discontinuous B-cell epitope prediction.
- HLA Class-I binding prediction.
- HLA Class-II binding prediction.
- Evaluation Criteria:
- Antigenicity.
- Surface accessibility.
- Allergenicity.
- Toxicity.
- Hydrophilicity.
- Final Selection:
- Select best epitopes.
- Design final vaccine construct.
6.6 Real-World Impact
- COVID-19 Vaccine Development:
- Traditional vaccine development: 10-15 years.
- COVID-19 vaccines (with bioinformatics): <1 year.
- Genome sequencing enabled rapid target identification.
- Computational tools accelerated design process.
- Clinical Trial Phases: (Not detailed, but implies acceleration)
| Benefits of Bioinformatics in Vaccine Development | Description |
|---|---|
| Time Reduction | From years to months. |
| Cost Efficiency | Lower research and development costs. |
| Safety | Better prediction of side effects. |
| Efficacy | Improved target selection. |
| Precision | Personalized vaccine approaches. |
7. SUMMARY OF KEY CONCEPTS
Bioinformatics Fundamentals:
- Interdisciplinary field combining biology + computer science + statistics.
- Essential for managing and analyzing large-scale biological data.
- Critical tool for modern biological research and drug discovery.
Database Importance:
- Organized storage of biological information.
- Multiple types serving different research needs.
- Public and private resources available.
- Continuously updated with new discoveries.
Vaccine Discovery Impact:
- Dramatically reduces development time.
- Enables rational vaccine design.
- Facilitates rapid response to emerging diseases.
- Improves safety and efficacy predictions.
PCI Verified Active 9 min read